
Use Case Studies
Adaptive redundancy in 5G: duplication-like reliability without paying the full price
25 Feb 2026
By the NanoPing team in collaboration with Aalborg University, and Mobile and Aerospace Networks Lab (Mobilenet) at the University of Malaga.
Short Summary
Public 5G can look great on coverage maps and still surprise you with ugly uplink spikes, especially outside dense urban areas. In real drive tests across commercial 5G NSA networks, always-on packet duplication gave the best tail-latency and loss, but it also doubled traffic. The standout compromise was Primary-Anchored Adaptive Failover (PAAF) with Partial Duplication: keep a designated primary link, and only duplicate packets when early-warning signals say the uplink is heading into bad coverage area. In the rural trace, that approach stayed close to full duplication while cutting the normalized redundancy cost by up to ~75%.
Key takeaways
- For low-latency applications, what hurts is usually the tails, not the median.
- Downlink (DL) performance can be stable while uplink (UL) goes off the rails; designing for UL is a different game.
- Link aggregation can still leave a heavy tail in rural scenarios when the UL becomes power- limited or links degrade together.
- Adaptive partial duplication is a practical best-effort pattern: stay efficient most of the time, then buy reliability only when needed.
5G can shine on downlink - uplink is where the constraints bite
If you judge 5G by the download experience, it's easy to be impressed: high peak rates, low jitter, and latency percentiles that don't wander much. The measurements in this study show the same pattern: DL latency percentiles remained comparatively stable across data rates, and they didn't exhibit the trace-capped extreme delay events that showed up on the UL.
But many real-time systems live or die on the UL path: telemetry, control traffic, sensor streams, acknowledgments, and anything that feeds a closed-loop controller. And the UL is fundamentally constrained by what the device can do. A phone, modem, or gateway has a hard transmit-power ceiling (around 23 dBm is typical). Once UL power control pushes the UE close to that ceiling, the link can't simply increment the transmission power to compensate for extra path loss. That's where latency tails and loss start to get interesting.
Why this problem is still hard in real 5G
If you've built systems for teleoperation, remote monitoring, industrial automation, or public- safety telemetry, you probably know the uncomfortable lesson: the median latency rarely kills the service performance, the outliers do. A few seconds of delay, or a short burst of losses, can be enough to break assumptions about safety, stability, or control.
5G helps a lot in many places—but the question the paper asks (and answers with real measurements) is a practical one:
When you need reliable low-latency communication, which multi-connectivity strategy actually works in commercial networks, and what does it cost?
Multi-connectivity: duplication vs. aggregation
Multi-connectivity (MC) is the basic idea of not betting everything on a single access path. In the paper, two classic strategies are compared:
- Packet duplication (selection diversity): send the same packet over multiple links; whichever copy arrives first wins. Great for killing tail latency, but expensive when alwayson.
- Link aggregation (traffic splitting / load sharing): split traffic across links without duplicating. In theory this reduces load on each link, but the UL often refuses to behave like the textbook model.
The message isn't “duplication good, aggregation bad”. It's that aggregation's effectiveness depends strongly on whether the UL is power-limited and whether the links degrade in a correlated way.
What has NanoPing actually done?
The authors ran measurement campaigns along urban, suburban, and rural routes using two commercial 5G NSA operators. Their telemetry setup captured (1) per-packet end-to-end latency and loss (separately for UL and DL), and (2) radio KPIs such as RSRP, uplink transmit power, and handovers sampled alongside the traffic.
Traffic was constant-bit-rate UDP with a fixed payload size of 1436 bytes. Telemetry snapshots were embedded regularly so radio conditions could be lined up with latency spikes.
To make the results actionable, they used simple “service suitability” indicators:
- One-way uplink latency target: 150 ms (used as a link-state indicator for control-like workloads)
- Late loss: packets arriving after 800 ms
- True loss: timeout at 10 seconds (packets not arriving within the evaluation window)
A rural step change when conditions start to struggle
One of the most striking rural observations is that performance doesn't always get gradually worse as signal strength fades. Instead, the UL can flip into a different regime. Once the UE is near its transmit-power limit, it can no longer compensate for additional path loss, and latency and packet loss jump upward in a step-like way.
The work visualizes this clearly around RSRP ≈ -100 dBm: above that region, latency samples are mostly compact; below it, the distribution spreads out dramatically and multi-second delays become common.
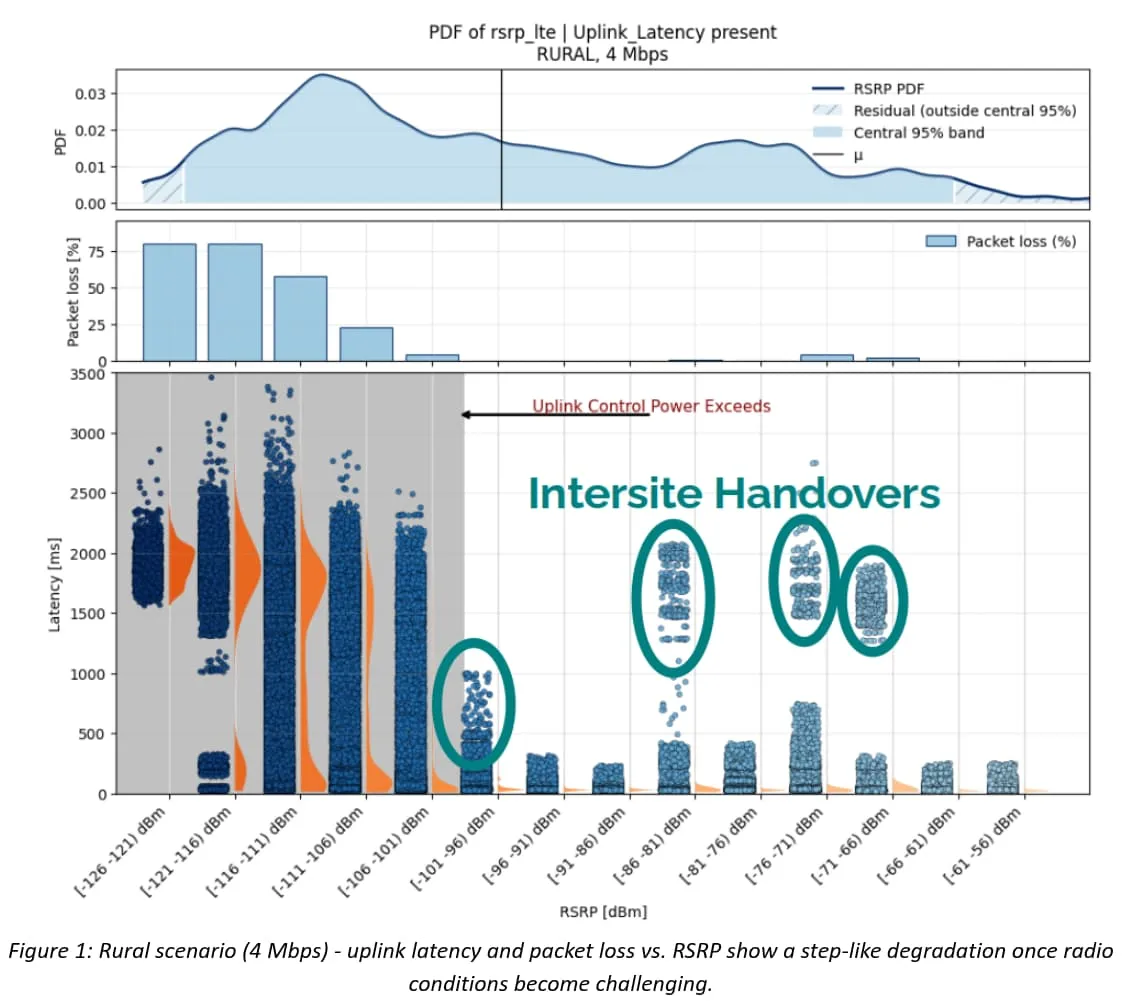
That step change lines up with UL power saturation: below the threshold, the UE is operating close to its power ceiling and retransmissions and queue build-up start to dominate the tail.
The part many people miss: UL Transmission power limits change the game
Why does this matter for multi-connectivity? Because once you're power-limited, small improvements in per-link load don't necessarily stop the bad state from happening. The study shows that reducing the rate per interface does not translate into a proportional drop in transmit power - the scheduler and power-control loop absorb much of the theoretical SINR margin.
Figure 2 connects the dots across environments: urban and suburban uplinks behave relatively smoothly, while rural samples spend far more time at high transmit power and show much larger latency excursions.
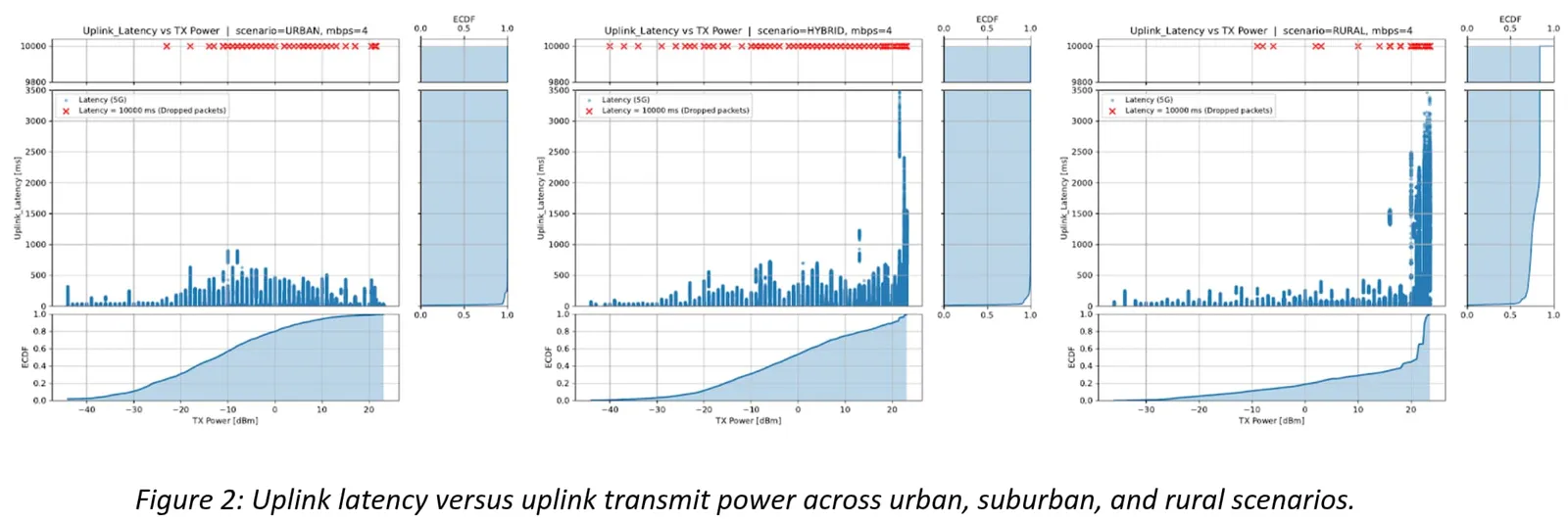
Why aggregation may not be useful in rural scenarios
It's tempting to think that splitting traffic across two links automatically makes each link's life easier. Often it does. But the rural measurements highlight why that intuition can break:
- When the UL is power-limited, halving the data rate per interface does not necessarily move the UE out of the stressed regime.
- If the two access links share similar propagation conditions (for example, co-located base stations), their degradations can be correlated.
- Under those conditions, aggregation may still leave retransmission bursts and queue buildup events untouched - exactly the events that dominate the extreme latency tail.
Why PAAF exists: static strategies are either expensive or too slow
From the experiments, the authors land on a familiar engineering trade-off. Full duplication is a strong upper bound on reliability, but it is expensive. Switching between links is cheap, but it can't always react fast enough to abrupt outages or short retransmission storms.
Their answer is Primary-Anchored Adaptive Failover (PAAF), a framework that keeps a designated primary link as the default and then adapts in two ways:
- PAAF Switching: move traffic to the secondary link when the primary starts looking bad.
- PAAF Partial Duplication (PD): keep sending on the primary, but duplicate packets over the secondary link when stress indicators trigger.
The “anchored” part is not just a technical choice; it matches how connectivity is often procured and operated in practice: there is usually a designated primary connection (for commercial and operational reasons), and a second one you use as backup or diversity when needed.
How PAAF Partial Duplication decides when to turn on redundancy
The work evaluates several trigger signals for activating duplication, including radio-only thresholds (RSRP, uplink transmit power), latency-only thresholds, and logical combinations of them. To avoid ping-pong behavior, the implementation uses minimum dwell times, with shorter dwell times when latency is part of the decision.
In plain terms:
- Latency is the truth signal - but it is reactive (you notice trouble after it starts).
- Radio KPIs can be earlier warnings - but they can be noisy if you use them blindly.
- Partial duplication benefits from early warning because you can start duplicating before the tail fully inflates.
The results are clear: near-duplication performance with a fraction of the overhead
The punchline shows up most clearly in the rural evaluation: PAAF Partial Duplication (PD) stays close to full duplication on latency and loss, while reducing normalized overhead by up to about 75% relative to always-on duplication.
In the rural 4 Mbps case, full duplication pays 100% overhead because every packet is sent twice. A strong PD policy - for example, activating duplication when (RSRP AND UL transmit power) OR latency crosses a threshold - uses duplication only during stressed periods. In the measurements, that yields overhead around 22.8% while keeping p95 and p99 uplink latency in the same range as full duplication, and pushing late/true loss down to the 10-3 range.
Table 1 compares the main strategies side by side and highlights the core trade-off: partial duplication reaches duplication-like tail latency while paying for redundancy only when the uplink is in trouble.

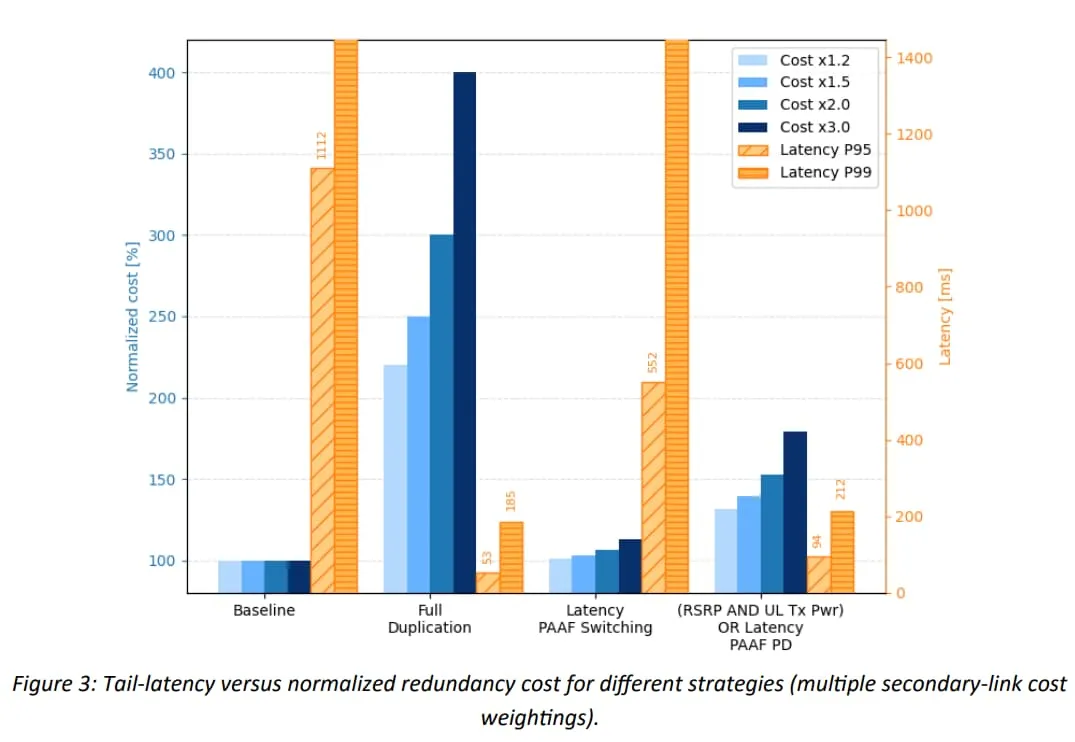
To put the table into a single picture, Figure 3 plots tail latency against normalized redundancy cost (using several weighting factors for the secondary link). It makes the same point visually: full duplication drives down the tail, but it pays a linear cost, while partial duplication sits in a favorable middle region.
What this means in practice
If you're designing a system that must tolerate rare but disruptive network events on public 5G, a few practical lessons fall out of this study:
- Do not equate good coverage with low latency: RSRP is useful context, but it is not a reliable standalone predictor of UL service quality.
- Assume uplink is the bottleneck in rural and sparse deployments: The measurements show uplink dynamics dominating variability and the worst outliers in rural conditions, while downlink stayed comparatively stable.
- Use redundancy tactically, not uniformly: Always-on duplication works, but it is expensive. Partial duplication is a template for spending redundancy where it has leverage.
- Prefer proactive triggers for fast bad states: Latency-only triggers are truthful but reactive. Radio KPIs can act as earlier warnings so duplication starts before the spike fully forms.
Would you like to develop a custom solution?
We'd love to hear from you. Whether you have a question about features, pricing, or anything else, our team is ready to help.
Contact us